AI Governance
Don’t Leave Your AI Agent Security Up to Chance


Does your organization currently have AI agents or agentic workflows in development – or maybe already in production? If so, what are your security and privacy goals for those systems? How are you testing their performance against those objectives? And when agents or workflows fall short of expectations, do you know which levers to pull to improve reliability, alignment, or compliance?
For most organizations, these questions reveal an uncomfortable truth: AI reliability and policy adherence are still more aspirational than measurable. Teams often have the right intentions – defined objectives, security policies, and model guardrails – but lack a structured way to evaluate how well their AI systems actually perform against those standards in real-world use. Even when data exists, it’s rarely connected to the architectural or probabilistic variables that drive those results.
Coalfire’s ForgeAI™ services and GuardianAI™ framework are designed to change that.
ForgeAI helps organizations translate abstract security and privacy goals into measurable performance metrics – making AI behavior observable, testable, and tunable. GuardianAI provides the architectural and analytical framework to pinpoint why deviations occur and what specific levers – technical, procedural, or design-related – can close the gap between intended and actual outcomes.
This combination of architectural rigor and operational testing transforms uncertainty into a controllable variable – bringing security, privacy, and reliability under the same measurable umbrella.
Understanding the Challenge as Nondeterminism
At the foundation of this effort lies a simple reality about how large language models actually work.
At their core, large language models (LLMs) operate on a principle known as next-token prediction. Given a set of tokenized inputs, the model calculates advanced sets of probability distributions of what the next token (or word fragment) is most likely to be, relative to those inputs.
From that distribution, response tokens are then sampled to form the model’s output.
In other words, every LLM response represents the result of probabilistic selection – not certainty.
Because of this, the reliability of an LLM’s output depends on the shape of its probability distribution and the many factors that influence both the distribution itself and how selections are made from it.
Example LLM Token Prediction Distribution
The practical question becomes: how can we influence this distribution so that the model produces outputs most likely to fall within the “desired” region of the curve – those outcomes aligned with our intent, policy, or requirements?
Many factors affect this reliability. The most obvious, of course, is the training process itself. If the model was trained on data that does not correlate with our prompts or domain, then even the best downstream controls will struggle to align it.
Modern frontier models – such as Claude, Gemini, or GPT – have achieved remarkable advances in reliability through massive datasets, reinforcement learning, and continuous optimization. However, reliability remains relative. Reality, model reasoning, and system controls will always exist slightly out of sync. As a result, nondeterministic outcomes – errors, hallucinations, or policy violations – remain an ongoing risk.
Influencing Reliability Without Retraining the Model
So, what can we do – those of us who aren’t model trainers or data scientists – to increase reliability in applied, operational contexts? Especially when the stakes involve security and privacy?
The answer lies in system design. We have numerous techniques available that allow us to influence the probability distribution without retraining the model. Here are some of the more effective techniques:
- Deterministic Interfaces. Enforce structured UI/UX patterns that constrain user prompts into validated, context-rich formats. (In other words, chat isn’t always king.)
- Task Decomposition. Break large, complex prompts into smaller, manageable sub-tasks to reduce error margin per inference.
- Model Selection. Choose models with known training data, quality controls, and domain alignment.
- Controlled Sampling Parameters. Configure the model API with tuned values for top_p and temperature to minimize creative deviation.
- Advanced Prompt Engineering. Craft prompts that provide explicit context, instructions, and intent framing to reduce ambiguity.
- External Context Integration. Use retrieval-augmented generation (RAG), APIs, or memory mechanisms to ground the model’s inference in reliable data.
- Quality Assurance and Feedback Loops. Apply pre-, mid-, and post-processing checks – both automated and human-in-the-loop – to detect and correct low-confidence or noncompliant results.
- Monitoring and Policy Filters. Enforce runtime guardrails that detect, score, or block outputs that violate safety, compliance, or policy thresholds.
If we put these tactics into practice, we can watch during testing as the standard deviation of accuracy and quality scores is impacted across a set of test runs.
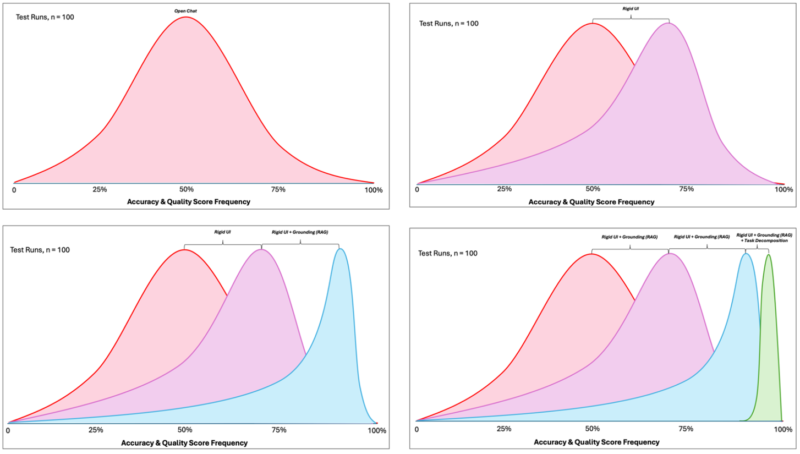
Layered Reliability Distributions
Applying the Framework to Security and Privacy Use Cases
Let’s translate this reliability framework into a security and privacy scenario. Imagine an AI agent deployed in an IT service management (ITSM) system, responsible for helping process support tickets. Your organizational policy is clear:
“No sensitive data is permitted to enter into the ticketing process.”
How do we enforce that policy reliably in a system driven by probabilistic inference?
- Deterministic Interfaces. Force ticket creation through existing ticketing UI or API where the agents are headless, and pulling from required ticket fields and descriptions with input enforcement.
- Integrated DLP Tools via MCP. Use data loss prevention (DLP) scanners – either external or embedded via an MCP server – to detect and stop policy violations in real time.
- Task Decomposition. Ensure there are separate agents that perform ticket completeness evaluation vs triage assessment vs routing logic etc. to reduce chances of policy hallucinations.
- Model Selection. Run model evaluation to identify if different models (between LLM vs SLM, Claude vs Gemini, etc.) perform better for the IT ticket processing and sensitive data policy adherence (or which models work best for different parts of the workflow).
- Controlled Sampling Parameters. Since IT ticketing is a type of workflow that require precision, configure the model API with tuned values for top_p and temperature to minimize creative deviation.
- Policy-Grounded Context (RAG). Integrate retrieval modules referencing your organization’s security and privacy policy at runtime, ensuring the agent’s context explicitly encodes those rules.
- Security-Aware Prompting. Engineer prompts to instruct the LLM that, if it detects sensitive data, it must immediately halt inference and trigger a human-in-the-loop alert.
- Runtime Guardrails (e.g., LLM Guards). Apply monitoring layers that filter for sensitive data types and flag or alert when detected.
- Quality Assurance and Feedback Loops. Position DLP gates at pre-, mid-, and post-processing checks – both automated and human-in-the-loop – to detect and correct low-confidence or noncompliant results.
This list is not exhaustive (and depending on initial baseline testing, may not all be needed) – but it illustrates how layered enforcement mechanisms can transform the likelihood of policy adherence from chance to something reflecting greater certainty. Below is an illustration of the prior test runs, this time within the context of security and privacy policy adherence.
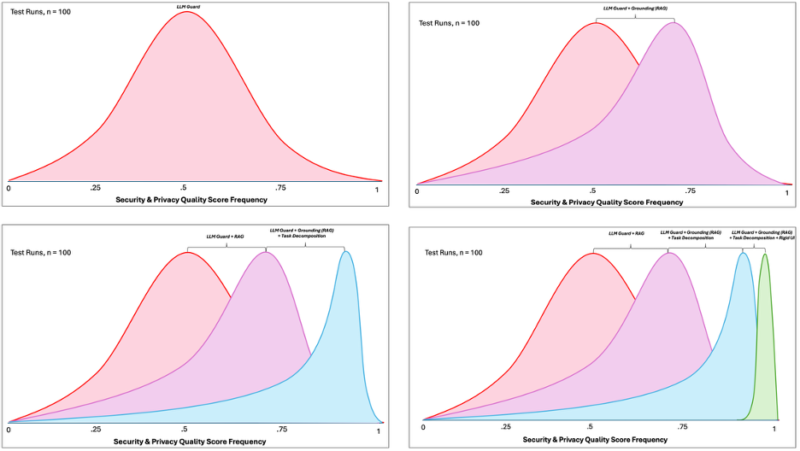
Applied Example: IT Ticketing Enforcement Curve
Why Many Guardrail Implementations Fail
Many organizations Coalfire engages with are still in the first wave of “guardrail” efforts, and it’s not uncommon for them to fail – not because the idea is wrong, but because the design understanding is shallow.
Security and privacy reliability in AI systems is not achieved by a single model-level guardrail or API setting.
It emerges from architectural composition – how we layer deterministic interfaces, context grounding, security policies, and probabilistic tuning to progressively reduce uncertainty.
In many deployments, these relationships are poorly understood or overlooked entirely at design time. Teams build on top of chat interfaces or integrate models without control points, unintentionally undercutting their own reliability ceiling.
The Path Forward with Coalfire’s ForgeAI Services
Security and privacy in AI are not static outcomes – they’re statistical objectives influenced by a laying of design decisions.
Coalfire’s GuardianAI framework and ForgeAI services treat reliability as a function of architectural layering, where each additional constraint systematically narrows the probability of undesired behavior.
Through this lens, we’re not merely filtering outputs for our customers – we’re engineering probability distributions toward risk and compliance objectives.